META-DESCRIPTION: This article examines a new reality where AI is not merely a tool on the periphery but rather the missing cognitive layer at the core of data quality management in the life sciences.
What if a clinical trial outcome was compromised not by a flawed protocol but by flawed data no one noticed?
What if the safety profile of a life-saving drug hinged on a misinterpreted pattern buried in an ocean of unstructured reports?
In the life sciences, every decision, from molecule to market, is governed by the integrity of data. The expectations are absolute: precision, traceability, and compliance. The AI-in-Life-Sciences market is evolving at warp speed, soaring from $12.43B in 2024 to a projected $29.3B by 2030, fueled by a relentless 15.32% CAGR. However, as data pipelines scale and digitization accelerates, an uncomfortable truth emerges: our ability to manage data quality has not kept pace with the complexity of the data itself.
Yes, traditional systems flag obvious errors or enforce static constraints. However, they cannot interpret relationships, infer context, or reason over incomplete datasets in clinically meaningful ways. That’s the hidden gap where today’s rule-based engines fall short, and tomorrow’s AI-native systems must rise.
This article explores a new reality: where AI is not a tool on the periphery but the missing cognitive layer at the core of data quality management in life sciences.
The Structural Weaknesses of Current Data Quality Systems
As data systems evolve and become more intricate, the ability to monitor and assess data quality diminishes, leading to potential inaccuracies and inefficiencies in decision-making processes. Understanding this relationship is crucial for developing more robust data quality frameworks that can effectively manage complexity while enhancing observability.
High Data Complexity, Low Observability
Life sciences data is inherently multidimensional. Clinical data spans EHRs, wearable telemetry, and lab results with inconsistent structures. Manufacturing data involves hierarchical process logs and conditional batch rules. Regulatory data often exists in semi-structured formats bound to submission taxonomies. Yet most data quality platforms continue to enforce static field rules. These fail to interpret data context, such as distinguishing a plausible deviation from a biologically impossible one or assess compound relationships across time series or ontological hierarchies.
Static Rules, Fragile Pipelines
Legacy quality assurance rules are labor-intensive to author and maintain. Worse, they decay with schema changes, jurisdictional shifts, or therapeutic context. A rule flagging “missing value in field X” doesn’t distinguish between permissible nulls (e.g., skipped visits) and protocol violations. Cross-field dependencies, such as dose adjustments based on renal function, are difficult to codify manually but essential for high-stakes validation. This reliance on human-written logic renders modern pipelines not only fragile but also operationally obsolete in dynamic, real-world data flows.
AI as a Cognitive Layer in the Data Quality Stack
AI’s true value isn’t just automation it’s cognition. It interprets data holistically, accounting for hidden structures, dynamic shifts, and domain nuance. Here’s how it transforms the data quality stack:
Semantic Understanding with Domain-Specific Language Models
Unlike static rule engines, AI models fine-tuned on clinical or regulatory corpora can read between the lines literally. They make sense of unstructured text, clinical notes, or error logs. They resolve entity mismatches like “aspirin” vs. “ASA” using synonym expansion, track inconsistencies across patient timelines, and even uncover hidden dependencies such as class-based drug effects. This shifts our approach; text is no longer treated as noise but as a vital signal.
Probabilistic Pattern Recognition Over Deterministic Logic
Instead of relying on rigid pre-coded rules, AI learns from past truths. For instance, time-series anomaly detectors can flag lab results that appear normal but deviate from a patient’s physiological history. Graph neural networks can map interdependencies across trial arms, treatment events, and adverse events, surfacing inconsistencies with clinical context in mind. This dynamic, probabilistic reasoning mirrors how clinical reviewers think only at scale.
Feedback-Driven Model Adaptation
AI systems evolve. When human stewards validate or override model suggestions, those choices loop back as reinforcement signals. Over time, the system becomes sharper, catching real anomalies, ignoring false alarms, and embedding expert judgment into the logic itself. This transforms data governance into a dynamic, learning process essential in rapidly evolving environments such as oncology trials or post-market safety surveillance.
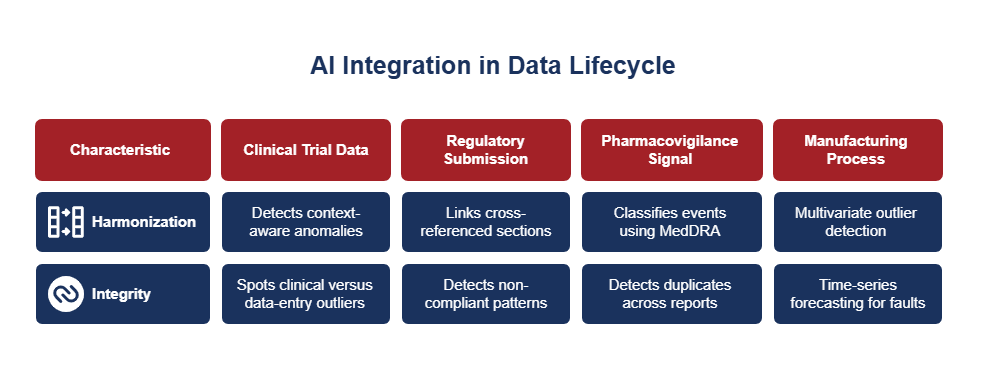
Deep AI Integration Across the Data Lifecycle
Incorporating AI into the data lifecycle not only harmonizes clinical trial data and ensures regulatory submission integrity but also enhances pharmacovigilance signal detection and reinforces manufacturing process quality.
A. Clinical Trial Data Harmonization
In multi-site trials, variability often slips past standard SDTM checks driven by protocol deviations, unit inconsistencies, or demographic differences. AI can fill these blind spots by automatically detecting context-aware anomalies, such as visit window misalignments triggered by local holidays. It learns cohort-specific baselines to spot clinical versus data-entry outliers and builds predictive models to flag sites with higher late-enrollment quality risk.
B. Regulatory Submission Integrity
Global submissions demand surgical precision across document structures, annexes, and metadata. AI helps by linking cross-referenced sections and flagging version mismatches. It can also detect non-compliant patterns across eCTD sequences and align structures with local regulatory schemas, whether it’s the FDA or CDSCO. Natural language processing, when combined with regulatory ontologies, forms a dynamic layer of compliance intelligence.
C. Pharmacovigilance Signal Integrity
Adverse event reporting is messy and inconsistent. AI trained on historical safety data can classify events using MedDRA through contextual NLP, detect duplicates across multilingual reports, and infer missing fields by comparing similar case histories. This boosts early signal detection and enhances narrative completeness for regulatory submissions.
D. Manufacturing Process Integrity
Rule-based monitors struggle with real-time production data from sensors, MES, and QC systems. AI strengthens quality oversight through multivariate outlier detection, time-series forecasting for early fault prediction, and validation of serialization and supply chain traceability supporting end-to-end, closed-loop control.
A Layered Architecture for AI-Led Quality Systems
Layer 1: Data Readiness
Start with ontology-aligned master data. Ensure metadata is clean, version-controlled, and fully traceable through lineage tracking.
Layer 2: AI Enablement
Train domain-specific models on historical quality errors. Design dual-mode pipelines that allow AI-inferred suggestions with human override.
Layer 3: Orchestration and Governance
Log every AI decision for provenance. Build explainability scaffolds to keep models auditable and regulatory-ready. Set strict validation gates before promoting model updates.
Conclusion
In life sciences, trust is sacred, rooted in the silent certainty that every data point, every outcome, and every protocol holds true. However, as data becomes more dynamic and intricate, legacy tools struggle to keep pace. AI is no longer an experiment at the edges it’s the inevitable foundation for quality in an era where decisions touch human lives.
At Trinus, we partner with life sciences leaders to embed learning systems that not only monitor data but also evolve with it. Because the future of quality isn’t static. It’s intelligent by design.
FAQs
Why can’t traditional rules-based systems alone manage data quality in life sciences?
Because they’re rigid and blind to nuance. Static rules don’t understand medical context, infer hidden relationships, or adapt to evolving data landscapes. AI can.
Can AI meet regulatory expectations in quality-critical domains?
Absolutely, if governed wisely. Life sciences organizations are adopting AI frameworks built on explainability, auditability, and human oversight to stay compliance-ready.
How soon can Indian pharma and biotech firms benefit from this shift?
Right now. With India’s growing global trial presence and manufacturing scale, AI-powered data quality ensures both credibility and resilience.
What’s the risk in adopting AI for data quality?
Not AI itself but AI without guardrails. Without versioning, traceability, and expert validation, models may drift or misfire. The solution? Governed AI as an adaptive ally, not an unchecked engine.